Understanding LSTM Networks
LSTM (Long Short-Term Memory)네트워크에 관한 이 문서의 원문은 여기에서 확인할 수 있습니다. LSTM 네트워크의 이해에 도움이 되는 좋은 내용이라 생각되어 꼼꼼히 읽어보고자 번역합니다.
재귀적 신경망(Recurrent Neural Networks)
당신은 어떻게 생각하고 있다고 생각합니까? 당신은 매 초마다 새로운 생각을 시작하지 않습니다. 당신은 이 글을 읽는 동안 언제나 이전 단어의 이해에 기반을 두어 현재의 단어들을 이해하는 방식으로 이 글을 이해할 것입니다. 즉, 모든 생각을 지워버리고 언제나 새로운 생각을 시작하지는 않는다는 것입니다. 그로 인해 당신의 생각과 이해는 지속성(persistence)을 가질 수 있게 됩니다.
전통적인 구조의 신경망은 지속성이 필요한 일들을 처리할 수 없습니다. 아마도 이것은 큰 결점일 것입니다. 예를 들자면, 영화를 관람할때 매시간마다 어떤 종류의 이벤트가 발생하는지를 분류하고 있다고 상상해 봅시다. 전통적인 뉴럴네트워크를 사용한다면, 어떻게 영화의 이전 사건에 대한 추론결과를 사용하여 현재의 이벤트를 분류할 수 있을지 확실치 않습니다.
재귀적 신경망은 이런 문제를 처리할 수 있습니다. 재귀적 신경망은 내부에 피드백 회로를 가지고 있는데, 이러한 구조적 특징 덕분에 정보가 지속적으로 처리되도록 할 수 있습니다.

피드백 회로를 가지고 있는 재귀적 신경망
위 다이어그램에서, 신경망 묶음 는 입력 를 받아들이고 를 출력으로 내보냅니다. 피드백 회로는 정보가 네트워크의 하나의 단계로부터 네트워크의 다음 단계로 통과하도록 허용합니다.
이러한 루프들은 재귀적 신경망을 다소 신비하게 보이도록 할지 모릅니다. 반면, 조금 더 생각해보면 보통의 신경망과 완전히 다르지는 않다는 것을 알 수 있습니다. 재귀적 신경망은 서로 다른 시점에서 작동하도록 되어있는 동일 네트워크의 여러 사본으로 생각할 수 있는데, 이들 각각은 다음 시점에서 작동하는 후임자 네트워크에게 메시지를 전달합니다. 재귀적 신경망의 루프를 풀면 어떻게 될지 한번 생각해 봅시다:
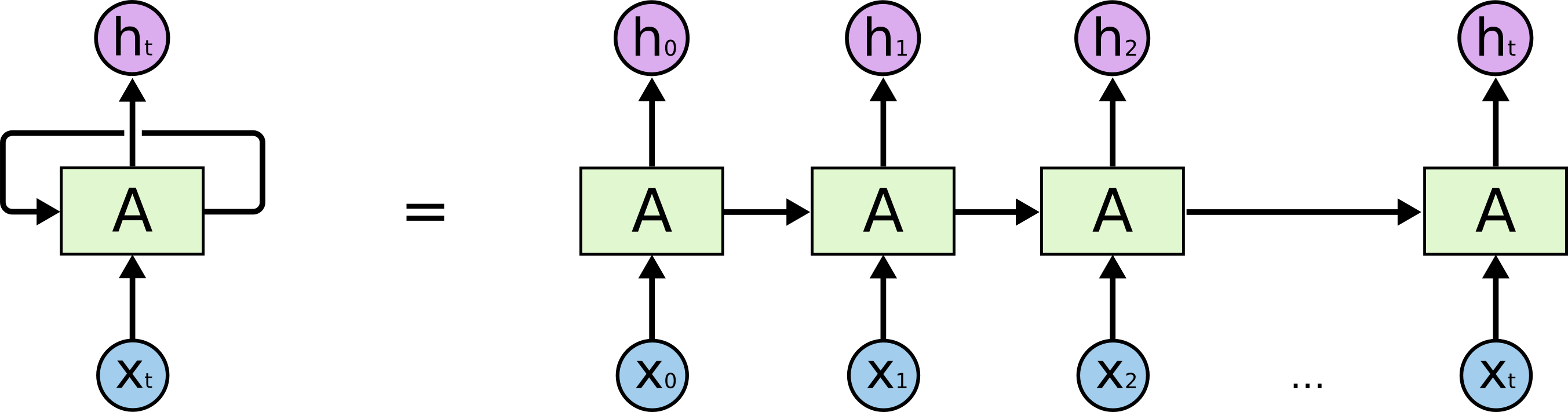
루프를 푼 재귀적 신경망
이러한 재귀적 신경망의 체인같은 성질은 재귀적 신경망이 시퀀스와 리스트 구조와 같이 순서가 있는 종류의 데이터에 밀접하게 관련되어 있다는 것을 암시합니다. 즉, 시퀀스와 리스트 데이터에 잘 적용할수 있는 신경망의 자연스러운 구조라는 것입니다. 과연 그럴까요?
재귀적 신경망은 확실히 시퀀스나 리스트 형태의 데이터를 처리하는데 이미 성공적으로 적용되고 있습니다. 지난 몇년 동안 음성인식, 언어모델링, 번역, 이미지 캡션과 같은 다양한 문제들에 대해 RNN이 성공적으로 응용되고 있습니다. 계속해서 Andrej Karpathy의 훌륭한 블로그 게시물인 Reason Neural Networks의 비상식적으로 좋은 효과를 살펴보면서, RNN으로 함께 달성할 수 있는 놀라운 업적에 대해서 논의하겠습니다. 실제로 그것들은 진짜로 훌륭히 일을 할 수 있습니다.
이러한 성공의 핵심은 바로 “LSTM 네트워크”를 사용하는 것인데, 이것은 매우 특별한 종류의 재귀적 신경망이며 많은 작업에 대해서 표준 버전의 재귀적 신경망보다 훨씬 효과적으로 작동합니다. 재귀적 신경망을 기반으로 한 거의 모든 흥미 진진한 결과는 바로 이 에세이에서 살펴볼 LSTM 네트워크와 함께 달성됩니다.
장기적 의존성의 문제(The Problem of Long-Term Dependencies)
RNN의 중요한 매력중 한가지는 이전의 비디오 프레임을 사용하여 현재 프레임이 가지는 의미를 분석하는 것처럼 이전의 정보를 현재의 작업에 연결할 수 있는 능력입니다. 만약 이를 수행할 수 있다면 RNN은 매우 유용할 것입니다. 이것이 가능할까요? 그것은 경우에 따라 좀 다를 수 있습니다.
때로는 현재의 작업을 처리하기 위해서 단지 최근의 정보만을 살펴봐야 할때도 있습니다. 예를 들어, 이전 단어를 기반으로 다음에 와야 할 단어를 예측하려고 시도하는 언어 모델을 생각해 봅시다. 우리가 “the clouds are in the sky” 라는 문장에서 마지막 단어를 예측하려고 한다면, 우리는 더 이상의 정보를 필요로 하지 않습니다. 다음 단어가 sky가 될 것이란 것은 매우 분명합니다. 그러한 경우, 즉 관련된 정보와 그것을 필요로 하는 장소 사이의 간격이 작은 경우에는, RNN은 과거의 정보를 사용하는 방법을 손쉽게 배울 수 있습니다.
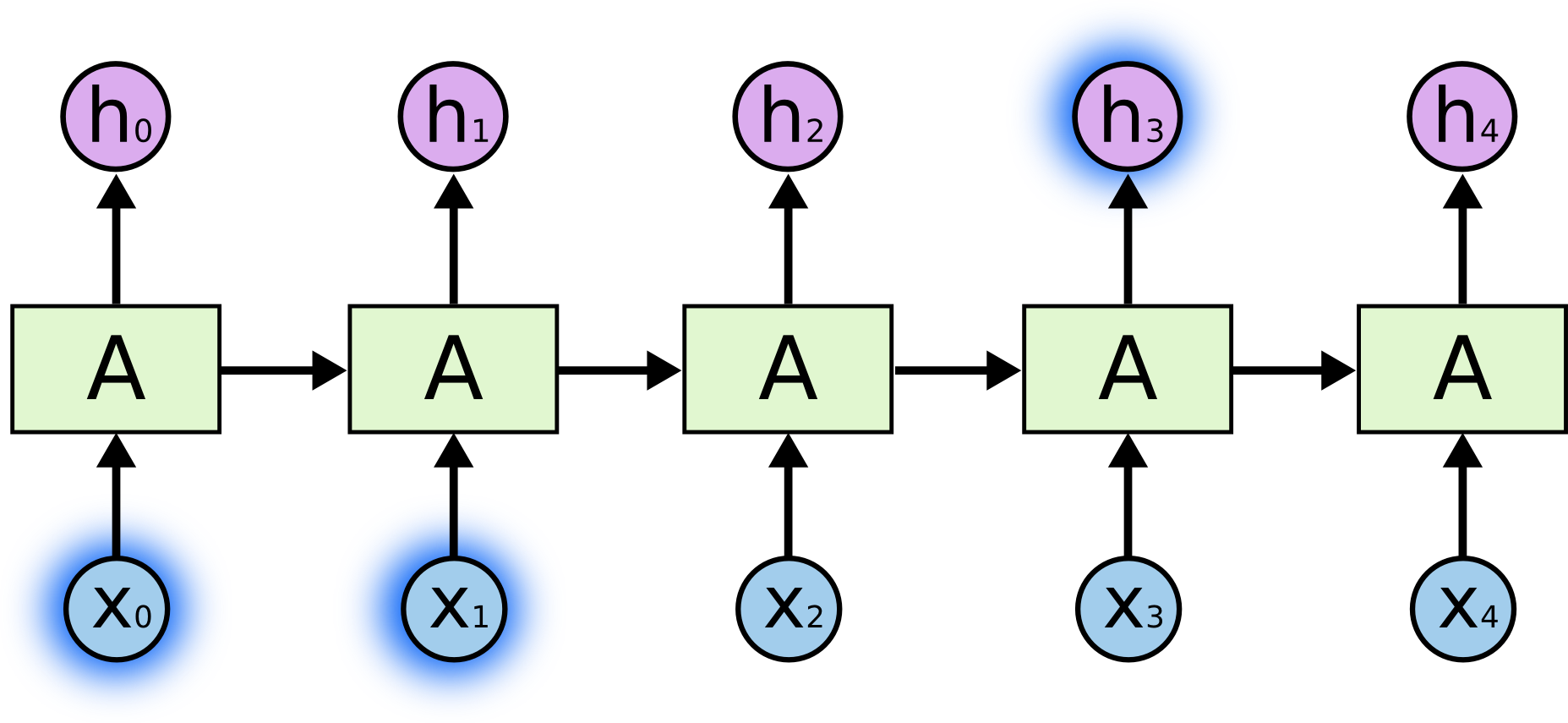
데이터가 단기적 종속성을 가지는 경우
그러나, 더 많은 맥락을 필요로 하는 경우도 있습니다. “I grew up in France… I speak fluent French.” 라는 텍스트에서 마지막 단어를 예측하려고 해봅시다. 마지막 단어의 최근 정보는 다음에 오는 단어가 아마도 언어의 이름이라고 제안할 수 있겠지만, 어떤 언어인지로 좁히기 위해서는, 더 뒤로부터 France가 나오는 문맥을 필요로 합니다. 연관된 정보와 그것이 필요해지는 시점 간의 간격이 매우 커지게 되는 상황은 전적으로 가능합니다. 불행히도 그 격차가 커지면 RNN은 정보를 연결하는 법을 배우기 어렵게 됩니다.
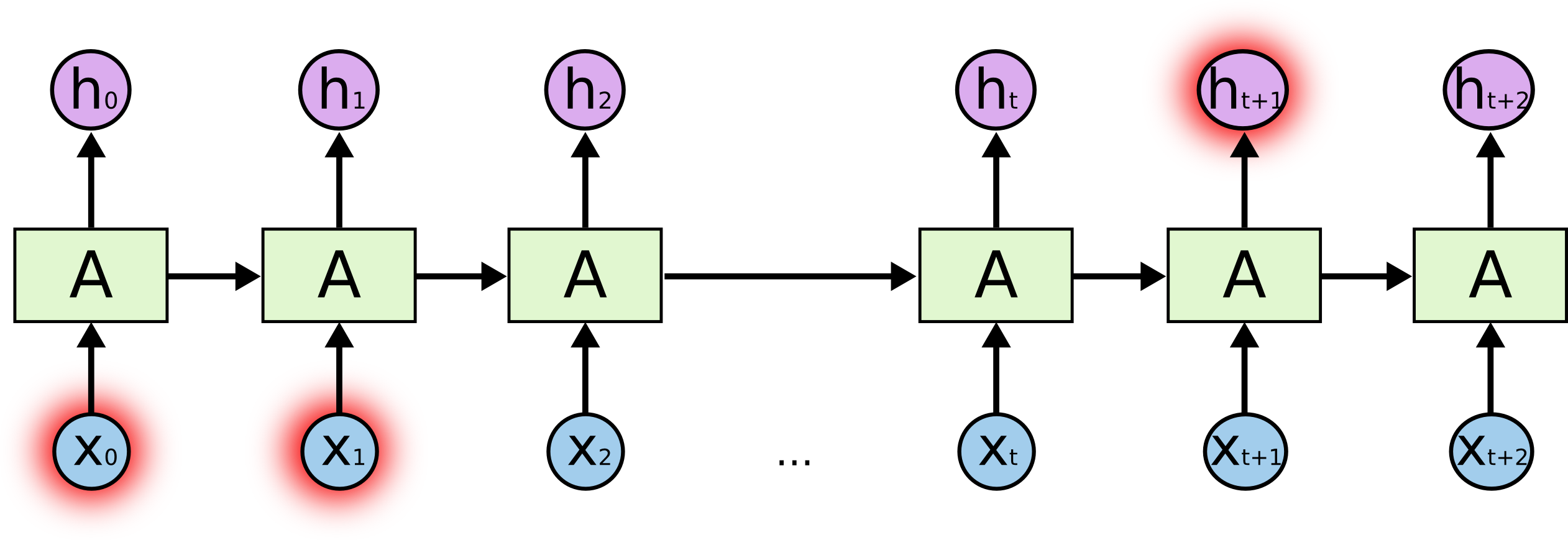
데이터가 장기적 종속성을 가지는 경우
이론적으로는 RNN이 이러한 “장기적 의존성”을 절대적으로 처리할 수는 있습니다. 인간이 이러한 형태의 쉬운 문제를 해결하기 위해서 신중히 매개변수를 선택할 수 있기 때문입니다. 그러나 슬프게도 실질적으로 RNN은 그러한 장기적 의존성 문제를 해결하도록 쉽게 학습할 수 있을 것 같지는 않습니다. 이 문제는 Hochreiter (1991) [독일]와 Bengio (1994)에 의해서 깊이 있게 조사되었는데, 그들은 이러한 장기적 의존성을 학습하는 문제가 해결되기 어려운 몇 가지의 매우 근본적 이유를 발견하였습니다.
고맙게도, LSTM 네트워크에는 이러한 문제가 없습니다.
LSTM Networks
Long Short Term Memory 네트워크 (일반적으로 “LSTM”이라고 함)는 특별한 종류의 RNN이며 장기 의존성을 학습할 수 있도록 설계되었습니다. 이것은 Hochreiter & Schmidhuber (1997)에 의해 소개되었고, 다음과 같은 업적을 남긴 많은 사람들에 의해 개선되고 대중화되었습니다. 이들은 다양한 문제에 대해 대단히 잘 작동하며 현재 널리 사용되고 있습니다.
LSTM은 장기 의존성 문제를 피하기 위해 명시적으로 설계되었습니다. 장기적 정보의 기억은 실질적으로 이 네트워크의 기본적인 행동이며 그러므로 어렵게 배울 필요가 없습니다!
모든 재귀적 신경망은 신경망의 반복적인 모듈 체인의 형태를 가집니다. 표준 RNN에서는, 이러한 재귀적으로 반복하는 모듈은 단일의 계층과 같은 매우 간단한 구조를 가집니다.
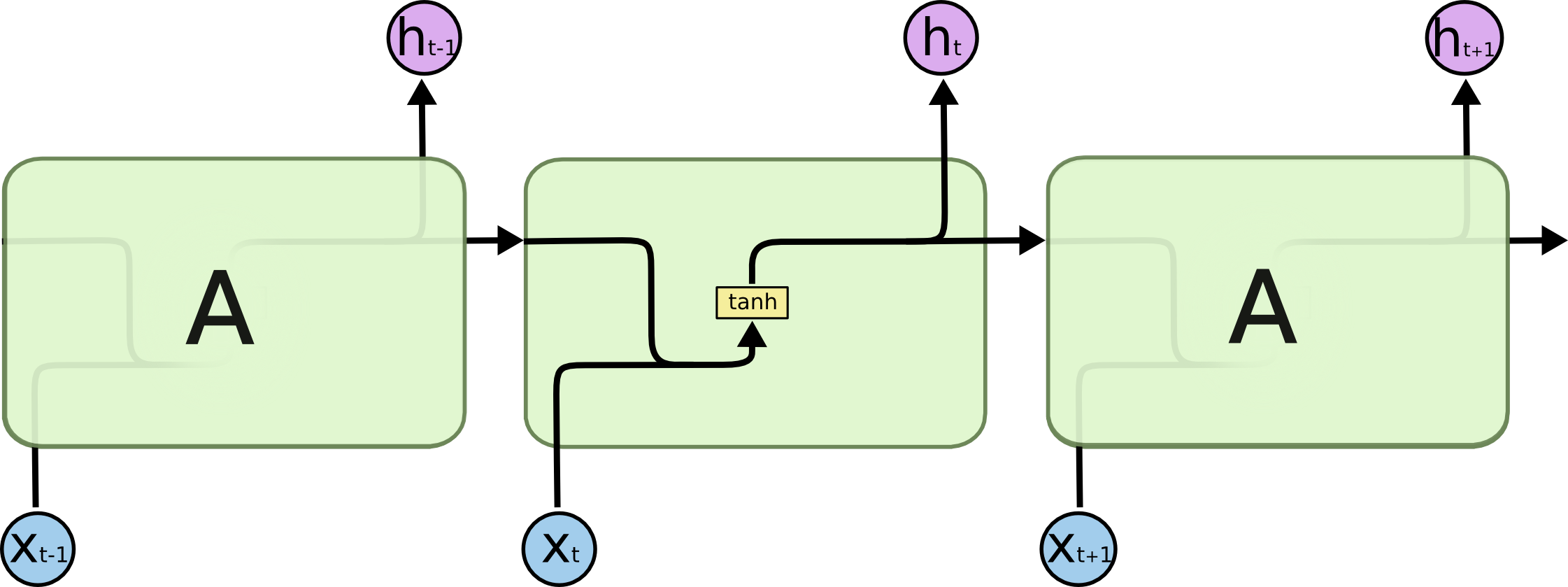
표준 RNN에서의 반복되는 모듈은 싱글 계층을 포함합니다.
LSTM 네트워크들도 이러한 체인구조를 가지지만, 그 반복 모듈들의 구조는 상이합니다. 단일의 뉴럴네트워크 구조를 가지는 대신에, 아주 특별한 방식으로 상호작용하는 4개의 계층을 가집니다.
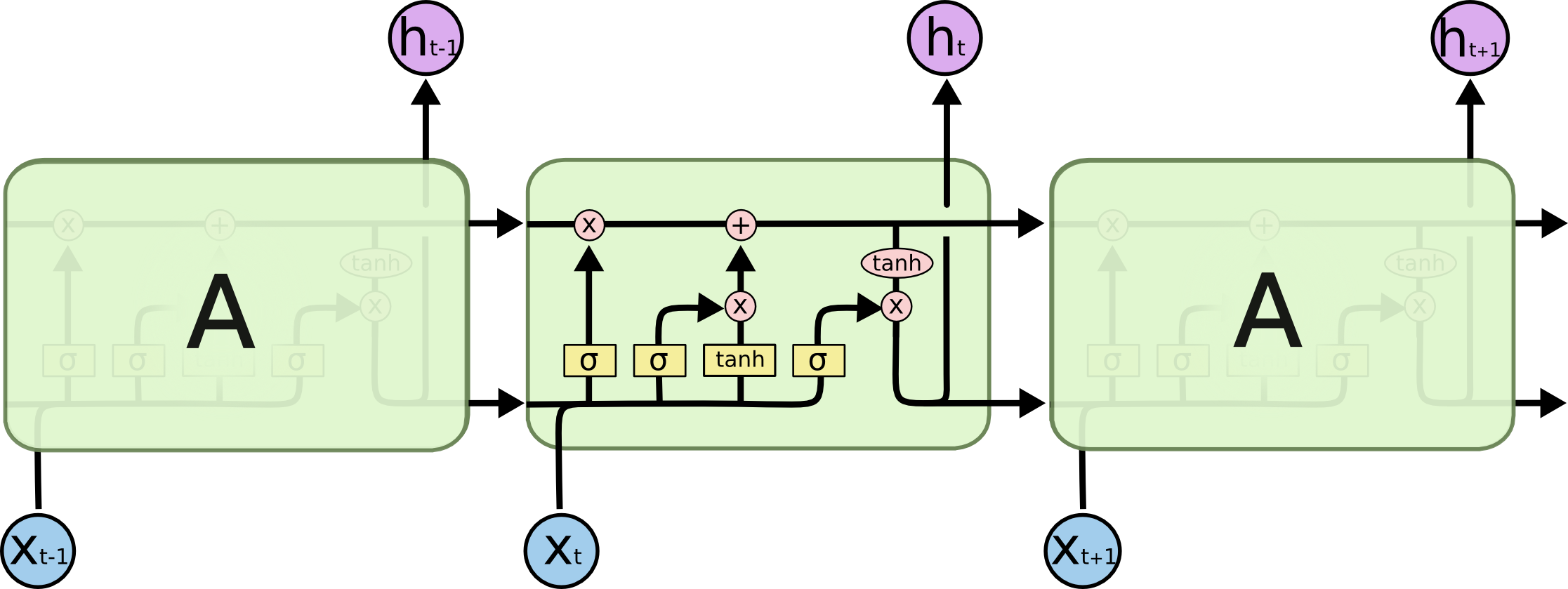
The repeating module in an LSTM contains four interacting layers.
무슨 일이 일어나는지에 대한 세부적 사항은 걱정할 필요가 없습니다. 우리는 나중에 LSTM 다이어그램을 단계적으로 살펴보도록 할 것이니까요. 지금은 사용하는 표기법에 익숙해 지도록 노력해 봅시다.

LSTM 네트워크 다이어그램의 표기법
위의 다이어그램에서 각 선은 한 노드의 출력에서 다른 노드의 입력까지 전체 벡터를 전달합니다. 핑크색 원은 벡터 추가와 같은 pointwise 연산을 나타내며, 노란색 상자는 뉴럴네트워크 계층을 학습한 것입니다. 병합되는 선은 연결을 나타내는 반면 분기는 내용이 복사되고 다른 선으로 이동한다는 것을 나타냅니다.
The Core Idea Behind LSTMs
LSTM의 핵심은 셀 상태이며 그것은 다이어그램의 상단을 가로 지르는 수평선입니다.
셀 상태는 일종의 컨베이어 벨트와 같습니다. 그것은 사소한 선형적 상호작용만을 하면서 체인 전체를 똑바로 따라갑니다. 정보가 변경되지 않고 그대로 전달되는 것은 매우 쉽습니다.
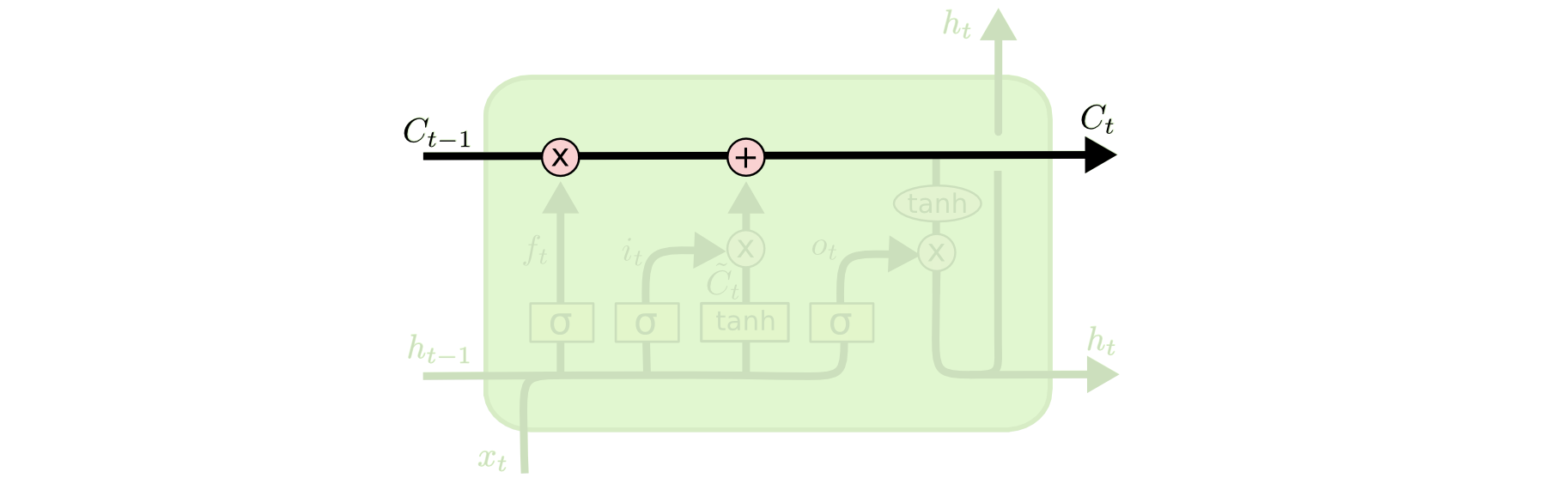
셀 상태
LSTM 네트워크에는 셀에서 정보를 제거하거나 추가할 수 있는 기능이 있는데, 이것은 게이트에 의해서 조심스럽게 조절됩니다.
게이트를 이용하여 선택적으로 셀에 정보를 전달할 수 있습니다. 그것들은 시그모이드 신경망 계층과 pointwise 곱셈 연산으로 구성되어 있습니다.
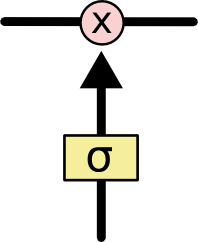
시그모이드 신경망 계층과 pointwise 곱셈연산으로 구성된 게이트
시그모이드 계층은 0과 1사이의 숫자를 출력함으로써 각 구성요소의 얼마 만큼을 통과시켜야 할지를 기술합니다. 0 값은 “아무 것도 통과시키지 말 것”을 의미하고 1 값은 “모든 것을 통과시킬 것”을 의미합니다.
LSTM 네트워크에는 셀 상태를 보호하고 제어하기 위한 세 개의 게이트가 있습니다.
Step-by-Step LSTM Walk Through
LSTM 네트워크의 첫번째 단계는 셀 상태로부터 벗어버릴 정보를 결정하는 것입니다. 이 결정은 망각 게이트 계층이라고 불리는 시그모이드 계층에 의해서 이루어 집니다. 그것은 과 를 보고 셀 상태인 에서 각 번에 대해서 과 사이의 숫자를 출력합니다. 은 “완전히 보존하라”는 것을 지시하며 은 “완전히 이것을 버려라”는 것을 지시합니다.
이전에 출현한 모든 단어들을 바탕으로 다음 단어를 예측하려고 시도하는 언어 모델의 예제로 돌아가 보겠습니다. 그러한 문제에서, 셀 상태에는 현재 대상의 성별이 포함될 수 있으므로 올바른 대명사를 사용할 수 있습니다. 새로운 주어가 보일 때, 우리는 이전 주어의 성을 잊기를 원할 것입니다.
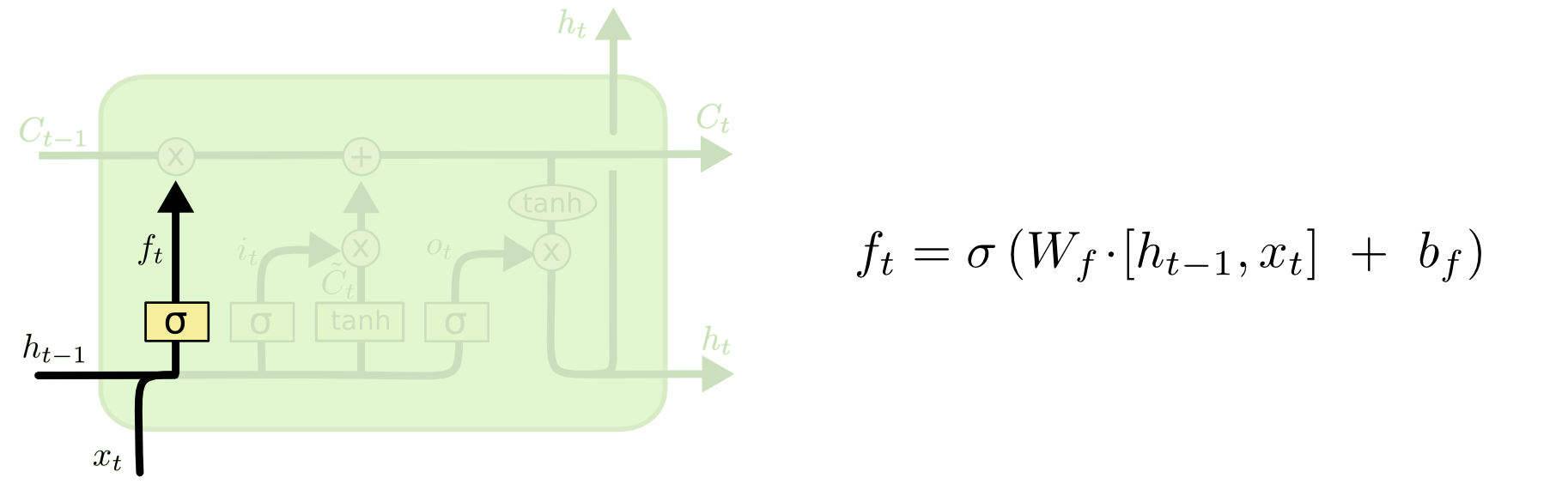
망각 게이트 레이어
다음 단계는 우리가 셀의 상태로 저장할 새로운 정보가 무엇인지 결정하는 것입니다. 여기에는 두 부분이 있습니다. 먼저 “입력 게이트 계층”이라고 하는 시그모이드 계층이 갱신할 값을 결정합니다. 그 다음, 계층은 상태에 추가될 수 있는 새로운 후보 값 벡터를 생성합니다. 다음 단계에서는 이 두 요소를 결합하여 상태를 업데이트합니다.
우리 언어 모델의 예제에서, 우리는 잊고자 하는 오래된 것(성별)을 대체하기 위해서 새로운 주어의 성별을 셀 상태에 추가하고자 합니다.
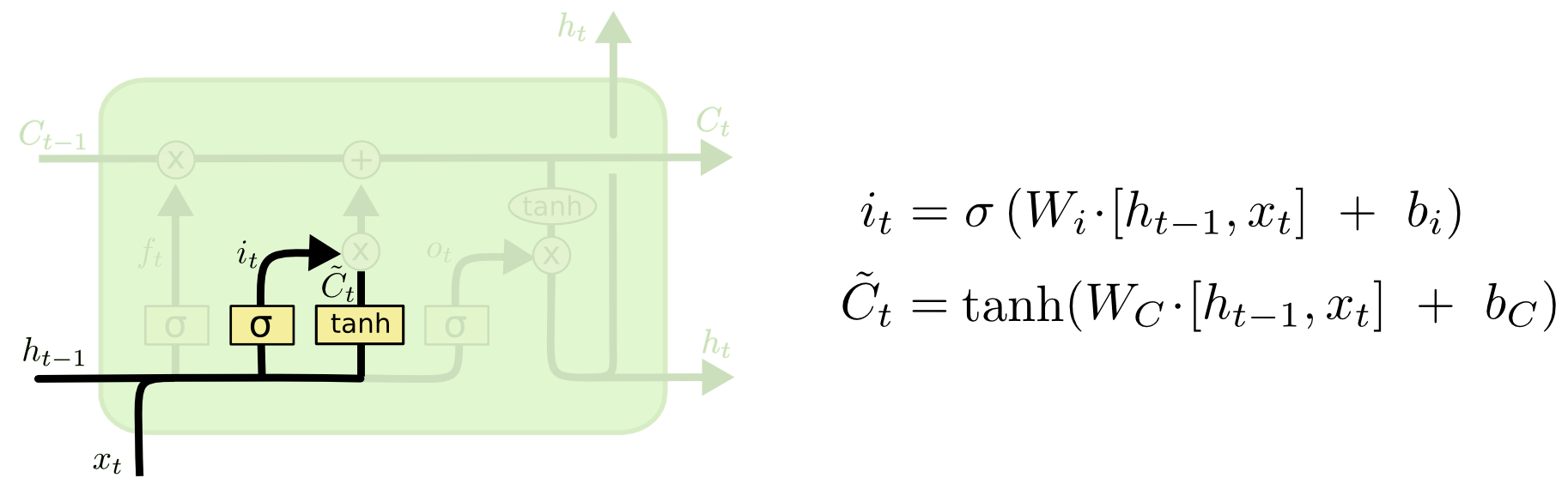
업데이트할 새로운 정보가 무엇인지 결정하기
이제는 이전 셀 상태 을 새로운 셀 상태 로 갱신해야 합니다. 이전 단계에서는 수행해야할 작업을 결정하였기 때문에 우리는 단지 실제로 그것을 수행하기만 합니다.
이전 상태에 로 곱하면서 이전에 잊어 버리기로 결정한 것들을 잊습니다. 그런 다음 를 더합니다. 이 값은 새로운 후보 값으로써, 각 상태 값을 얼마나 많이 업데이트하기로 결정하였는지의 정도에 따라서 조정됩니다.
언어 모델의 경우 이전 단계에서 결정한대로 이전 주어의 성별에 대한 정보를 삭제하고 새로운 정보를 추가합니다.
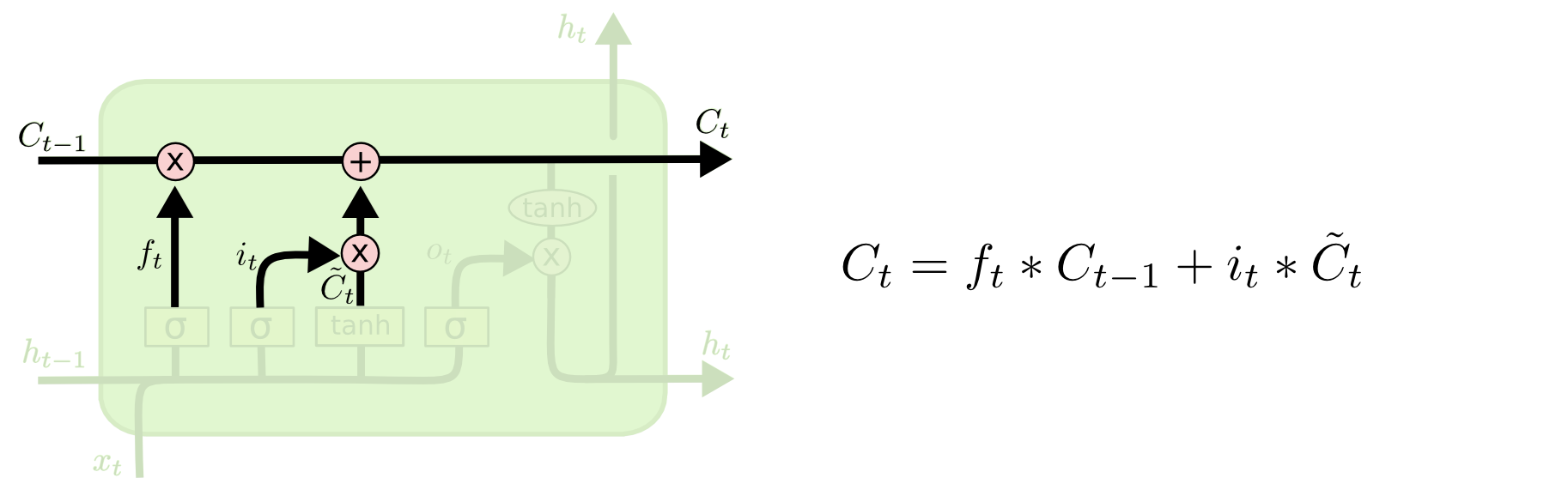
셀의 상태를 새로운 정보로 갱신하기
마지막으로 출력할 내용을 결정할 필요가 있습니다. 이 출력은 셀의 상태에 기반을 두지만 필터링된 버전이 됩니다. 먼저, 출력할 셀 상태의 일부분을 결정하는 시그모이드 레이어를 실행합니다. 그 다음에는 를 통해 셀 상태를 설정하고 (값을 과 사이로 밀어 넣으십시오) 시그널 게이트의 출력을 곱해서 우리가 결정한 부분만을 출력하게 합니다.
언어 모델 예제의 경우에는 단지 주어를 보았으므로 다음에 올 동사와 관련된 정보를 출력 할 수 있습니다. 예를 들어 주어가 단수인지 복수인지를 출력할 수 있으므로 다음에 오는 동사가 어떤 형태로 결합되어야 하는지 알 수 있습니다.
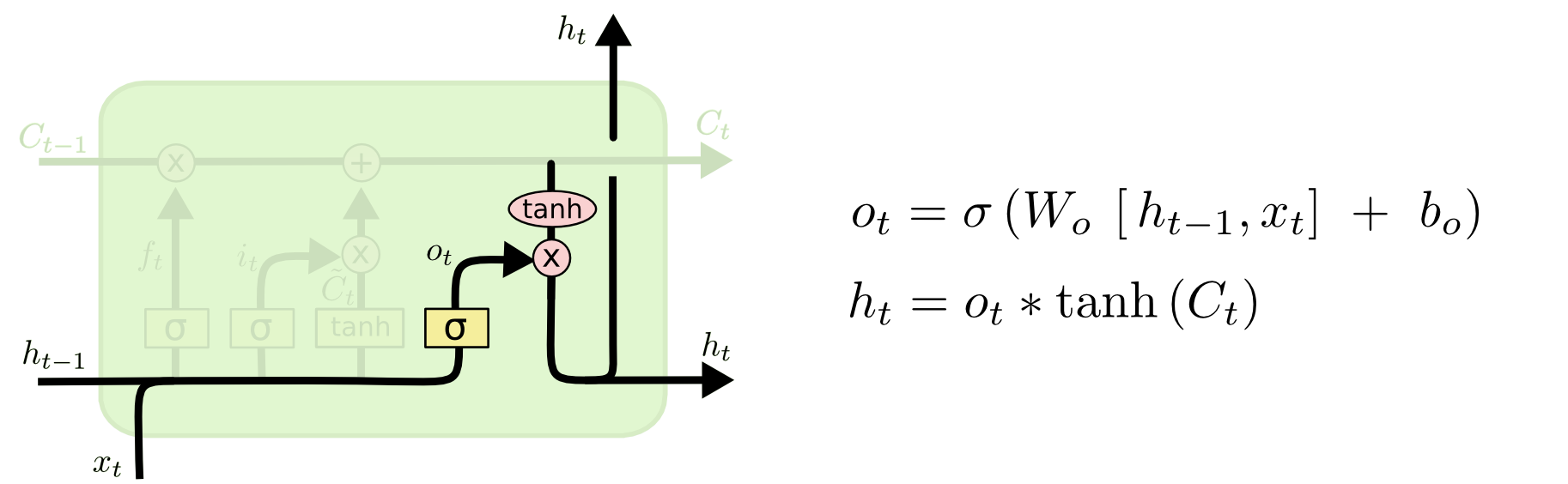
출력한 내용을 결정하기
LSTM의 변종(Variants on Long Short Term Memory)
지금까지 설명한 것은 꽤 일반적인 LSTM 네트워크입니다. 그러나 모든 LSTM 네트워크가 위와 동일한 것은 아닙니다. 사실, LSTM 네트워크를 포함하는 거의 모든 연구가 조금씩 상이한 버전을 사용하는 것처럼 보입니다. 그 차이는 사소하지만 그 중 일부는 언급 할만한 가치가 있습니다.
Gers과 Schmidhuber (2000)에 의해서 소개된 인기있는 LSTM 네트워크의 변종 중 한가지는 Peephole connections가 추가된 모델입니다. 이것은 게이트 레이어가 셀 상태를 보게 한다는 것을 의미합니다.
주) Peephole은 엿보기라는 의미입니다.
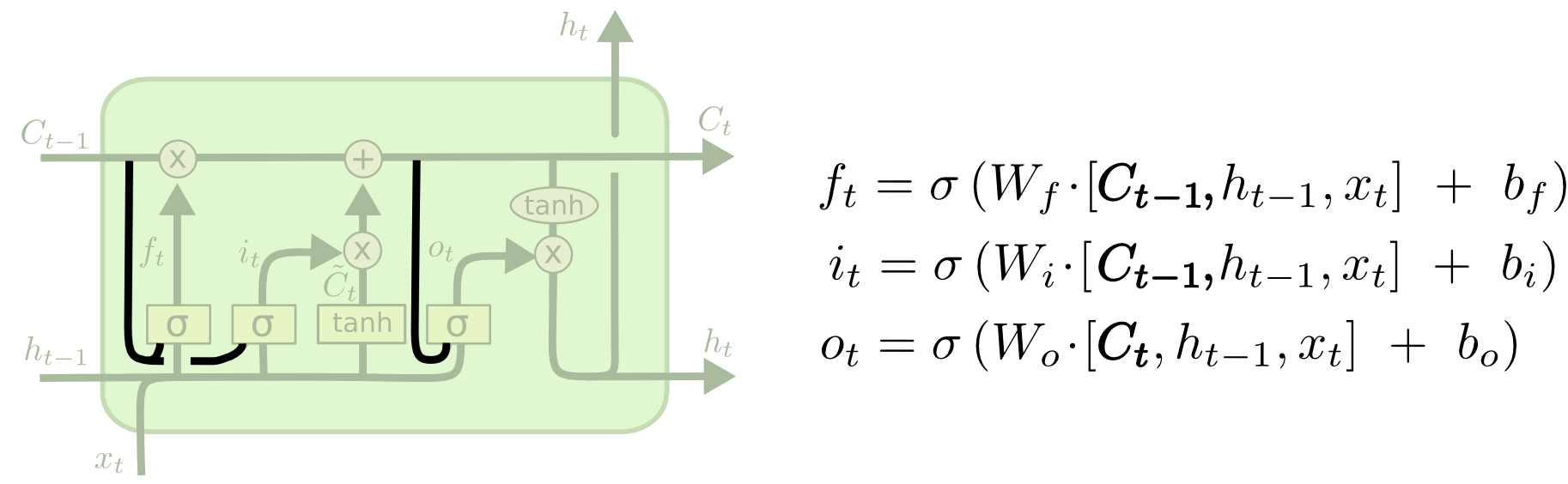
Peephole connections가 추가 된 LSTM의 변종
위의 다이어그램은 모든 게이트에 peephole을 추가하고 있습니다만, 많은 논문들이 peephole을 일부 게이트에만 추가하거나 또는 다른 논문들에서는 peephole을 추가하고 있지 않습니다.
또 다른 변형은 망각(forget) 및 입력이 결합된 게이트를 사용하는 것입니다. 여기서는 망각할 정보와 새로운 정보를 추가해야하는 정보를 별개로써 결정하는 대신, 우리는 이러한 결정을 함께합니다. 그 자리에 무언가를 입력 할 때에만 잊어 버립니다. 우리는 더 오래된 것을 망각할 때에만 새로운 값을 그 상태에 입력합니다.
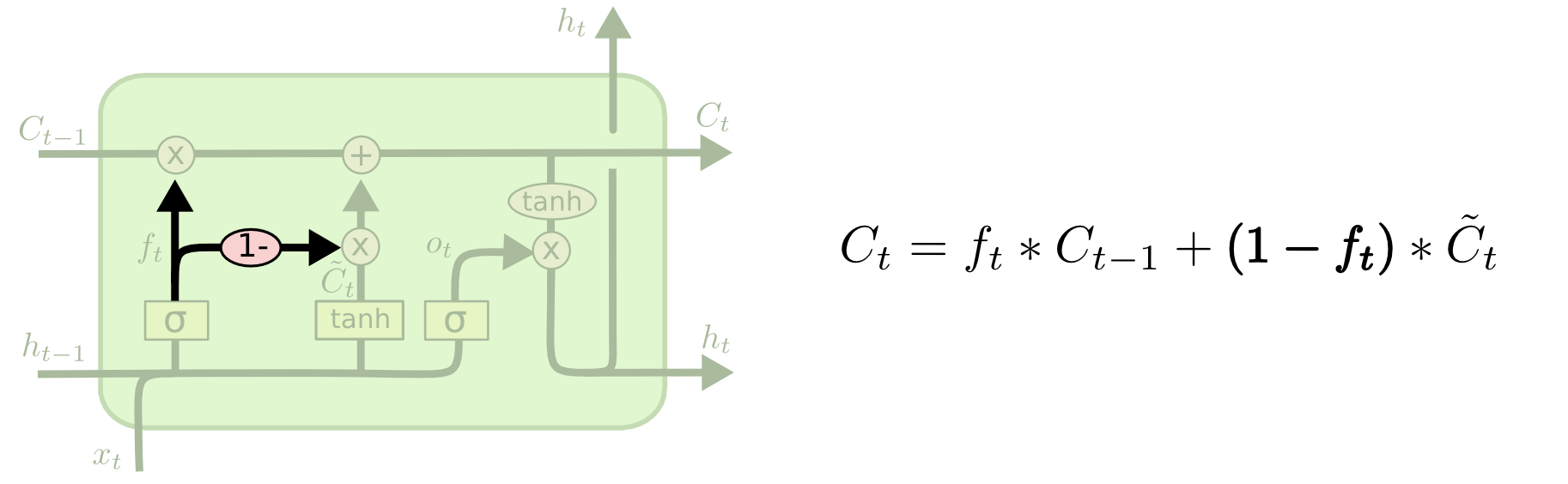
망각과 입력이 결합된 게이트
LSTM 네트워크에 조금 더 극적인 변종은 Gated Recurrent Unit(GRU)입니다. 이것은 (Cho et al., 2014)에 의해서 도입되었습니다. 이것은 망각 게이트와 입력 게이트를 하나의 “업데이트 게이트”에 결합합니다. 또한 셀 상태와 숨겨진 상태를 병합하고 다른 변경 작업도 수행합니다. 결과로 생성 된 모델은 표준 LSTM 네트워크 모델보다 간단하며 점차 대중화되고 있습니다.

Gated Recurrent Unit(GRU)
이들은 가장 주목할 만한 LSTM 네트워크의 변종 중 단지 몇 가지에 지나지 않습니다. (Yao et al., 2015)에 의한 Depth Gated RNNs 과 같은 많은 것들이 있습니다. (Koutnik et al., 2014)에 의한 Clockwork RNNs와 같은 장기 의존성에 대한 완전히 다른 접근법도 있습니다.
이러한 변종중에서 어느 것이 최상일까요? 그런 차이들이 중요할까요? (Greff et al., 2015)는 인기있는 변종을 잘 비교하였고, 그들이 거의 동일하다는 것을 알게 되었습니다. (Jozefowicz et al., 2015)는 10,000 개 이상의 RNN 아키텍처를 테스트하여 특정 작업에서 LSTM보다 더 잘 작동하는 일부를 찾아 내기도 하였습니다.
Conclusions
여기서는 RNN으로 달성한 주목할만한 몇가지 결과들을 언급하였습니다. 본질적으로 이들 모두는 LSTM 네트워크를 사용하여 달성되었고 이것들은 실제로 대부분의 작업에 대해서 표준 재귀신경망보다 더 잘 작동합니다.
LSTM 네트워크는 일련의 방정식으로 작성된 것으로 처음에는 매우 두렵게 보일지도 모릅니다. 바라건대, 이 에세이를 통해서 단계별로 밟아 나간다면 좀 더 접근하기 쉬울 것입니다.
LSTM 네트워크는 RNN을 통해서 도달할 수 있었던 중요한 발자취입니다. 다음과 같이 궁금해 하는 것은 당연합니다: 또 다른 큰 걸음이 있습니까? 연구자들의 일반적 의견은 “예! 다음 단계가 있습니다만, 주의를 기울이십시오”. 그 아이디어는 RNN의 모든 단계에서 정보를 수집하고, 좀 더 큰 정보의 컬렉션에서 바라보는 것입니다. 예를 들어 RNN을 사용하여 이미지를 설명하는 캡션을 만드는 경우 이미지의 일부를 선택하여 출력하는 모든 단어를 볼 수 있습니다. 사실, (Xu et al., 2015) 정확하게 이것(역자: 주의와 관련한 연구)을 하십시오 - 주의(attention)는 정말로 재미있는 연구의 시작점인지 모릅니다. 주의를 이용하여 벌써 흥미 진진한 결과들이 많이 나왔고, 모퉁이를 돌면 훨씬 더 흥미로운 것들이 많이 있을 것입니다.
RNN연구에서 주의가 유일하게 흥분되는 주제는 아닙니다. 예를 들어, (Kalchbrenner et al., 2015)의 Grid LSTMs는 매우 유망해 보입니다. 또한, 생성 모델에서 RNN을 사용한 연구들, 예를 들면 (Gregor et al. 2015), (Chung et al., 2015), (Bayer and Osendorfer, 2015) 또한 매우 흥미로워 보입니다. 이와 같이 지난 몇 년간은 재발성 신경망이 진보한 매우 흥미 진진한 시기였습니다.